
Small data-set accuracy

Explainable AI
Online learning
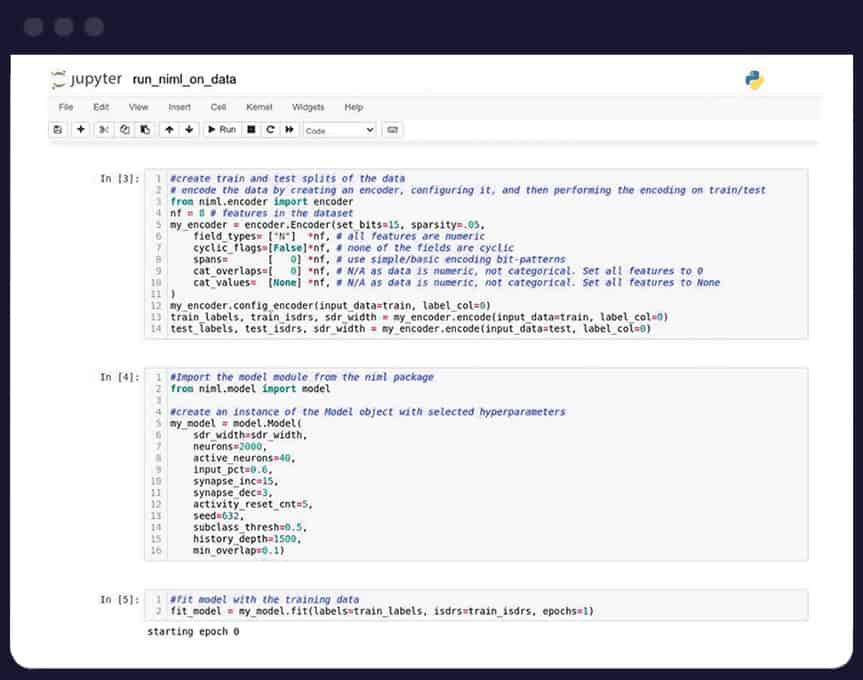
Unsupervised Learning
Reduce need to curate and label data to build Machine learning model
Incremental Training
Add new classes without retraining entire model

Explainable Results
Delivers rich semantic information about prediction from input to output

Anomaly detection
High resolution decision boundaries clearly identify new signatures



